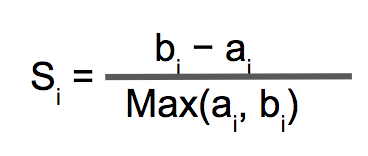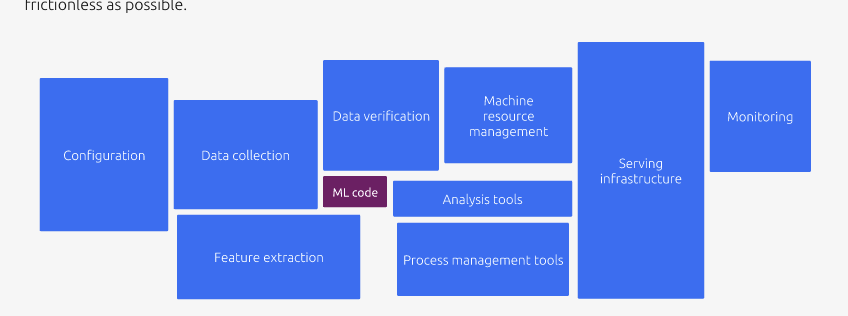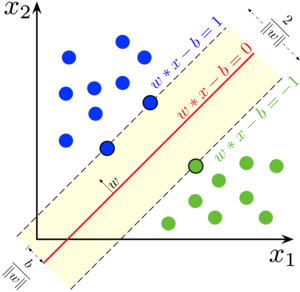
概览支持向量机(Support Vector Machine)是一种二类分类模型。基本原理是,特征空间上几何间隔最大化。
In its most simple type, SVM doesn’t support multiclass cl
2021-01-20