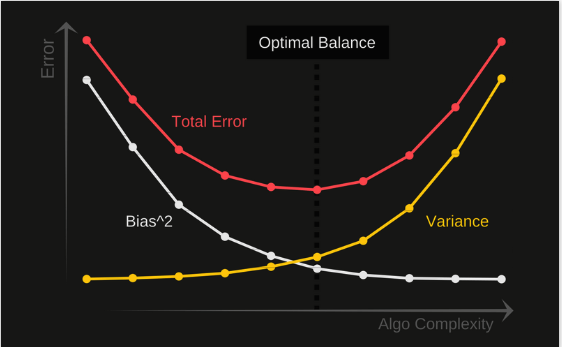
集成多个算法结果得到比任何单个算法更好的结果,称为集成学习。
常见的集成学习方法有:
- 贝叶斯最优分类器
- Bootstrap aggregating(又称 Bagging)。代表算法随机森林。
- Boosting。代表算法 AdaBoost、XGBoost。
- 贝叶斯参数平均(Bayesian Parameter Averaging, BPA)
- 贝叶斯模型组合(BMC)
- 桶模型(Bucket of models)
- Stacking(堆叠泛化)
Bootstrap Aggregating
又称 Bagging,代表算法随机森林。集成模型中的每个模型在投票时具有相同的权重。为了减小模型方差,Baging使用随机抽取的子训练集训练集成中的每个模型。例如,随机森林算法将随机决策树与Bagging相结合,以实现更高的分类准确度。
- 每个基评估器相互独立。
- 基评估器准确率得高于0.5。
随机森林的效果为什么比单个模型好?
假设有三个分类器,每一个准确率是0.8。少数服从多数原则下投票时,任意两个以上分类正确,集成结果也会正确。任意两个以上分类正确的概率参考如下公式: 3* (0.8)^20.2+1(0.8)^3*1=0.896
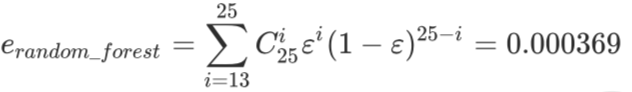
Boosting
代表算法 AdaBoost、XGBoost。Boosting通过在训练新模型实例时更注重先前模型错误分类的实例来增量构建集成模型。在某些情况下,Boosting已被证明比Bagging可以得到更好的准确率,不过它也更倾向于对训练数据过拟合。
- 基评估器是相关的、按顺序构建的。
Stacking(堆叠泛化)
首先,使用可用数据训练所有其他算法,然后训练组合器算法以使用其他算法的所有预测作为附加输入进行最终预测。通常用逻辑回归模型作为组合器。