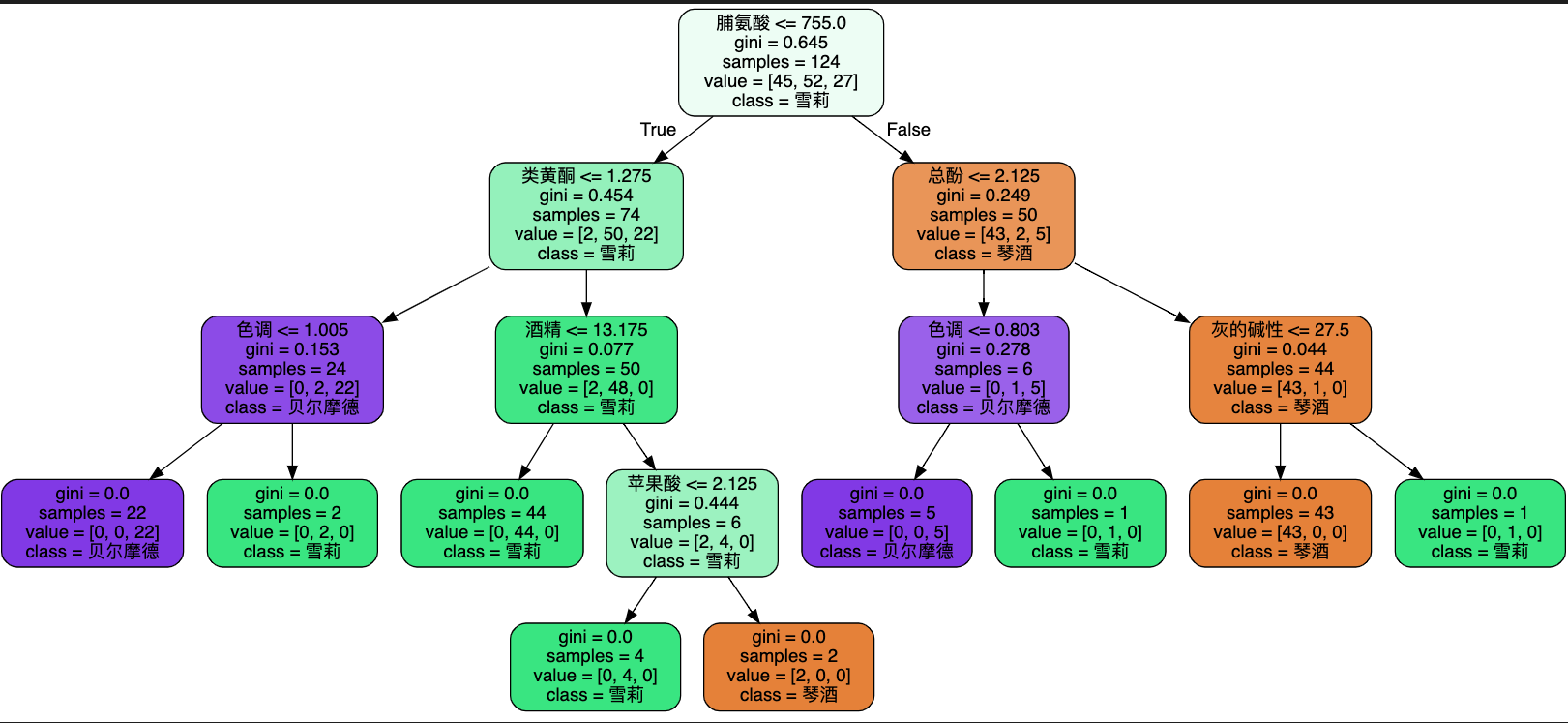
Entropy vs gini
sklearn.tree.DecisionTreeClassifier(criterion="gini") 中 criterion 参数用于指定节点上决策问题评估指标(不纯度降低量最大或信息增益最大),有两种选择:
entropy,使用信息熵(Entropy)衡量数据集包含的信息量;父节点信息熵减去子节点(左右子节点求和)信息熵作为信息增益;挑出带来信息增益最大的切分数据问题作为父节点决策问题。gini,使用基尼不纯度(Gini Impurity)衡量数据的不纯度;父节点不纯度减去子节点(左右子节点求和)不纯度作为不纯度降低量;挑出带来不纯度降低量最大的切分数据问题作为父节点决策问题。
对比
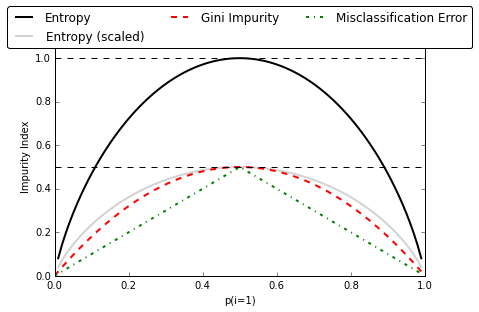
- 信息熵对数据集的不纯度更加敏感(原因见上图 ),因此决策树的生长会更加“精细”,对于高维数据或者噪音很多的数据,很容易过拟合;
- 信息熵的计算比基尼系数缓慢一些,因为基尼系数的计算不涉及对数。
其他