TensorFlow Extended 是什么?
Google 开源的端到端平台,用于部署生产型机器学习流水线。
TFX Core Concepts
TFX Pipelines
A TFX pipeline defines a data flow through several components, with the goal of implementing a specific ML task (e.g., building and deploying a regression model for specific data). Pipeline components are built upon TFX libraries. The result of a pipeline is a TFX deployment target and/or service of an inference request.
A TFX pipeline is a sequence of components that implement an ML pipeline which is specifically designed for scalable, high-performance machine learning tasks.
Artifacts
In a pipeline, an artifact is a unit of data that is passed between components. Generally, components have at least one input artifact and one output artifact. All artifacts must have associated metadata, which defines the type and properties of the artifact. Artifacts must be strongly typed with an artifact type registered in the ML Metadata store.
Model vs. SavedModel
Model
A model is the output of the training process. It is the serialized record of the weights that have been learned during the training process. These weights can be subsequently used to compute predictions for new input examples. For TFX and TensorFlow, ‘model’ refers to the checkpoints containing the weights learned up to that point.
SavedModel
What is a SavedModel: a universal, language-neutral, hermetic, recoverable serialization of a TensorFlow model.
Why is it important: It enables higher-level systems to produce, transform, and consume TensorFlow models using a single abstraction.
SavedModel is the recommended serialization format for serving a TensorFlow model in production, or exporting a trained model for a native mobile or JavaScript application
Schema
Some TFX components use a description of your input data called a schema. The schema is an instance of schema.proto.
The schema can specify data types for feature values, whether a feature has to be present in all examples, allowed value ranges, and other properties.
One of the benefits of using TensorFlow Data Validation (TFDV) is that it will automatically generate a schema by inferring types, categories, and ranges from the training data.
In a typical TFX pipeline TensorFlow Data Validation generates a schema, which is consumed by the other components.
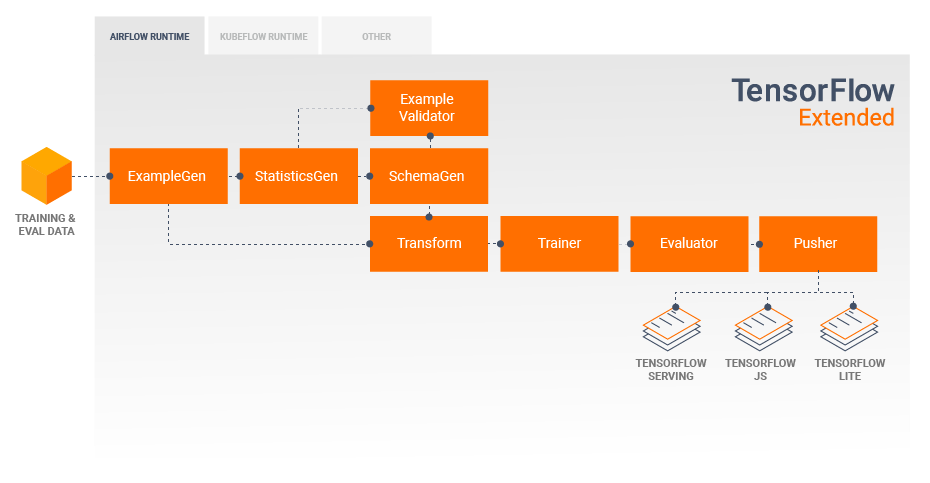
TFX Pipeline Components
A TFX pipeline typically includes the following components:
- ExampleGen: initial input component of a pipeline that ingests and optionally splits the input dataset.
- StatisticsGen: calculates statistics for the dataset.
- SchemaGen: examines the statistics and creates a data schema.
- ExampleValidator: looks for anomalies and missing values in the dataset.
- Transform: performs feature engineering on the dataset.
- Trainer: trains the model.
- Evaluator: performs deep analysis of the training results and helps you validate your exported models, ensuring that they are “good enough” to be pushed to production.
- Pusher: deploys the model on a serving infrastructure.
Anatomy of a Component
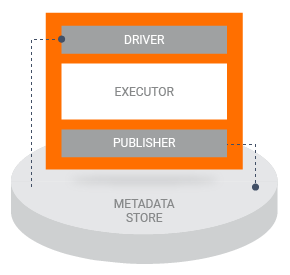
TFX components consist of three main pieces:
Driver and Publisher
The driver supplies metadata to the executor by querying the metadata store, while the publisher accepts the results of the executor and stores them in metadata. As a developer you will typically not need to interact with the driver and publisher directly, but messages logged by the driver and publisher may be useful during debugging.
Executor
The executor is where a component performs its processing. As a developer you write code which runs in the executor, based on the requirements of the classes which implement the type of component that you’re working with. For example, when you’re working on a Transform component you will need to develop a preprocessing_fn.
TFX Libraries
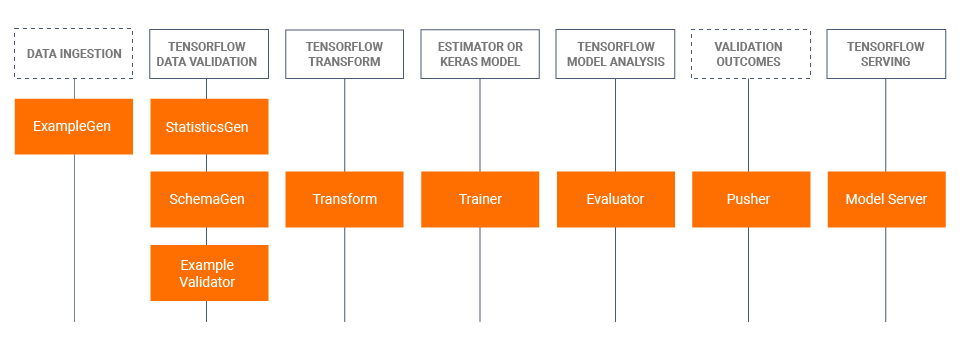
TFX includes both libraries and pipeline components.This diagram illustrates the relationships between TFX libraries and pipeline components:
TFX libraries include:
- TensorFlow Data Validation (TFDV) is a library for analyzing and validating machine learning data.
- TensorFlow Transform (TFT) is a library for preprocessing data with TensorFlow.
- TensorFlow is used for training models with TFX.
- TensorFlow Model Analysis (TFMA) is a library for evaluating TensorFlow models.
- TensorFlow Metadata (TFMD) provides standard representations for metadata that are useful when training machine learning models with TensorFlow.
- ML Metadata (MLMD) is a library for recording and retrieving metadata associated with ML developer and data scientist workflows.
Technologies Behind TFX
TFX is a Google-production-scale machine learning platform based on TensorFlow.
- based on TensorFlow
Apache Beam is an open source, unified model for defining both batch and streaming data-parallel processing pipelines. TFX uses Apache Beam to implement data-parallel pipelines.
- Apache Beam
Developing with TFX
TFX provides a powerful platform for every phase of a machine learning project, from research, experimentation, and development on your local machine, through deployment.
Data Exploration, Visualization, and Cleaning
TFX pipelines typically begin with an ExampleGen component, which accepts input data and formats it as tf.Examples.Often this is done after the data has been split into training and evaluation datasets so that there are actually two copies of ExampleGen components, one each for training and evaluation.
ExampleGen component accepts input data and formats it as tf.Examples; Split data into training and evaluation dataset.
a StatisticsGen component and a SchemaGen component, which will examine your data and infer a data schema and statistics.
examine data and infer a data schema and statistics.
ExampleValidator component consumes schema and statistics will look for anomalies, missing values, and incorrect data types in your data.
look for anomalies, missing values, and incorrect data types.
TensorFlow Data Validation (TFDV) is a valuable tool when doing initial exploration, visualization, and cleaning of your dataset.
TFDV examines your data and infers the data types, categories, and ranges, and then automatically helps identify anomalies and missing values. It also provides visualization tools that can help you examine and understand your dataset.
Following your initial model training and deployment, TFDV can be used to monitor new data from inference requests to your deployed models, and look for anomalies and/or drift. This is especially useful for time series data that changes over time as a result of trend or seasonality, and can help inform when there are data problems or when models need to be retrained on new data.
TFDV can be used to monitor new data;especially useful for time series data ;
Data Visualization
You will first query ML Metadata (MLMD) to locate the results of these executions of these components, and then use the visualization support API in TFDV to create the visualizations in your notebook.
Developing and Training Models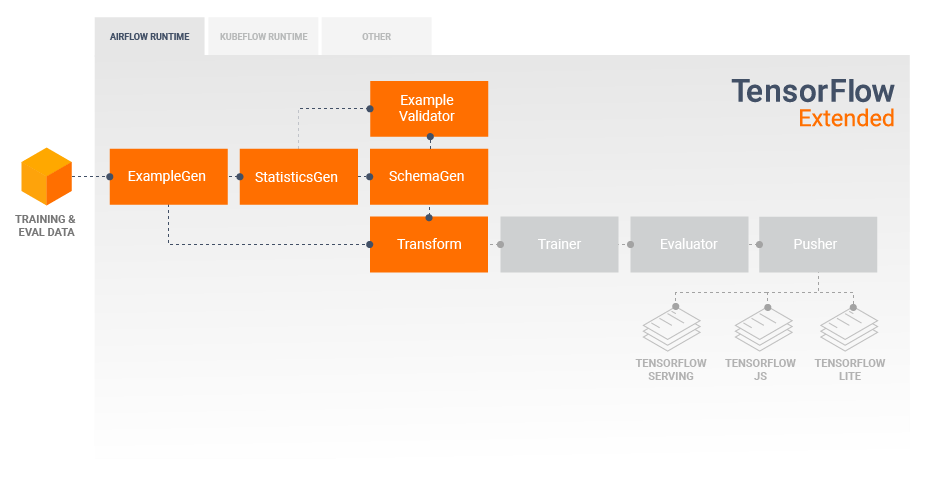
A typical TFX pipeline will include a Transform component, which will perform feature engineering by leveraging the capabilities of the TensorFlow Transform (TFT) library.
feature engineering;
A Transform component consumes the schema created by a SchemaGen component, and applies data transformations to create, combine, and transform the features that will be used to train your model.
consumes the schema;data transformations
Cleanup of missing values and conversion of types should also be done in the Transform component if there is ever a possibility that these will also be present in data sent for inference requests.
Cleanup of missing values and conversion of types;
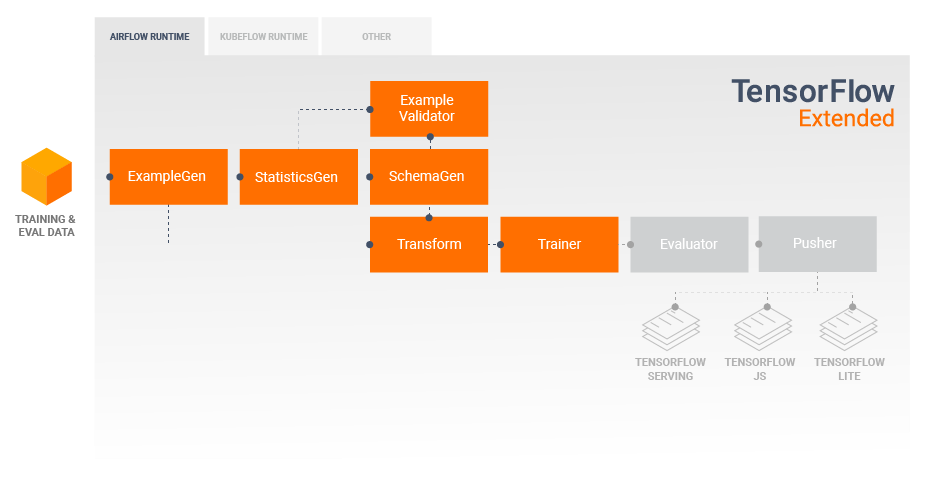
The result of a Transform component is a SavedModel which will be imported and used in your modeling code in TensorFlow, during a Trainer component.
The result of a Transform component is a SavedModel ????
This SavedModel includes all of the data engineering transformations that were created in the Transform component, so that the identical transforms are performed using the exact same code during both training and inference.
SavedModel includes all of the data engineering transformations.
Using the modeling code, including the SavedModel from the Transform component, you can consume your training and evaluation data and train your model.
During the last section of your modeling code you should save your model as both a SavedModel and an EvalSavedModel.
Saving as an EvalSavedModel will require you to import and apply TensorFlow Model Analysis (TFMA) library in your Trainer component.
Analyzing and Understanding Model Performance
Following initial model development and training it’s important to analyze and really understand you model’s performance.
A typical TFX pipeline will include an Evaluator component, which leverages the capabilities of the TensorFlow Model Analysis (TFMA) library, which provides a power toolset for this phase of development.
An Evaluator component consumes the EvalSavedModel that you exported above, and allows you to specify a list of SliceSpecs that you can use when visualizing and analyzing your model’s performance.
Evaluator component consumes the EvalSavedModel;specify a list of SliceSpecs that you can use when visualizing and analyzing your model’s performance.
Each SliceSpec defines a slice of your training data that you want to examine, such as particular categories for categorical features, or particular ranges for numerical features.
SliceSpec defines a slice of your training data that you want to examine;
Model Analysis and Visualization
you can visualize the results in a Jupyter style notebook. For additional runs you can compare these results as you make adjustments, until your results are optimal for your model and application.
visualize the results in a Jupyter style notebook;compare these results as you make adjustments
Deployment Targets
Once you have developed and trained a model that you’re happy with, it’s now time to deploy it to one or more deployment target(s)
TFX supports deployment to three classes of deployment targets.
TensorFlow Serving; TensorFlow Lite;TensorFlow JS
Trained models which have been exported as SavedModels can be deployed to any or all of these deployment targets.
SavedModels can be deployed to deployment targets.
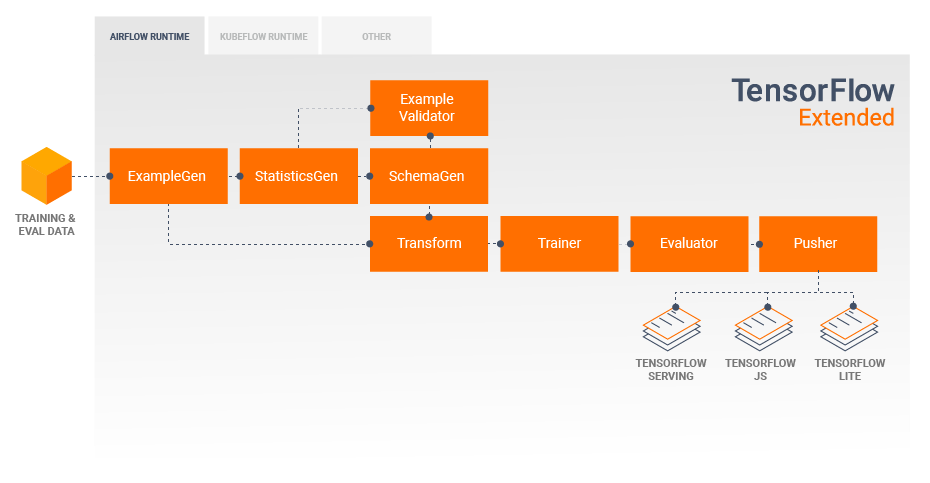
Inference: TensorFlow Serving
TensorFlow Serving (TFS) is a flexible, high-performance serving system for machine learning models, designed for production environments.
designed for production environments.
It consumes a SavedModel and will accept inference requests over either REST or gRPC interfaces.
consumes a SavedModel ;accept inference requests
It runs as a set of processes on one or more network servers, using one of several advanced architectures to handle synchronization and distributed computation.
one or more network servers;synchronization and distributed computation.
In a typical pipeline a Pusher component will consume SavedModels which have been trained in a Trainer component and deploy them to your TFS infrastructure. This includes handling multiple versions and model updates.
Pusher component will consume SavedModels,and deploy them to your TFS infrastructure;handling multiple versions of models